You can also be interested in these:
- Intel enters the GPU game with its Xe-HPG (DG2)
- New Intel XeSS AI Super Sampling: More FPS in games
- Comparison of the Z790 and Z690 Intel motherboard chipsets
- Who leads the battle of the CPUs in 2023?
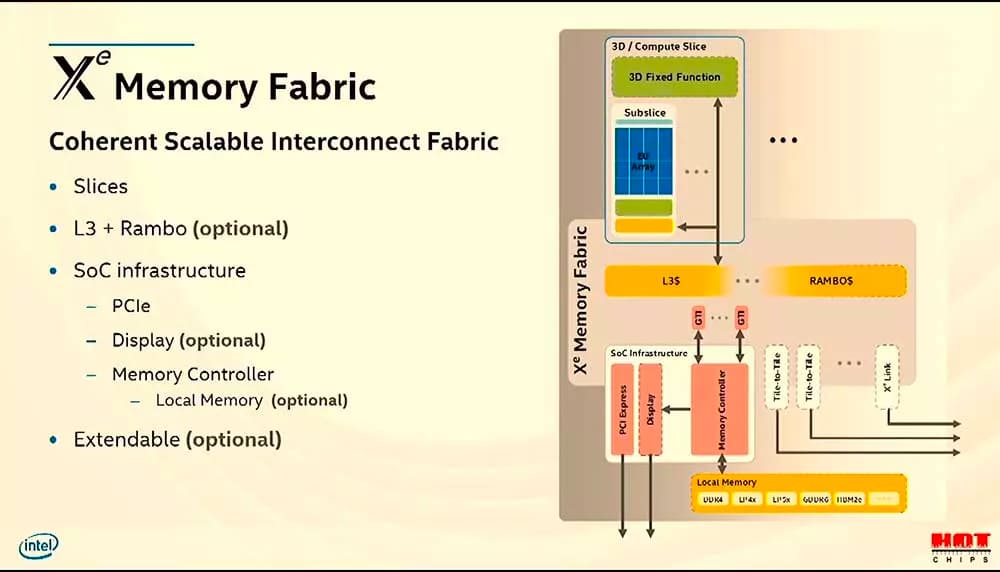
During his presentation in 2019 about the future of Intel Xe architecture, Raja Koduri mentioned a type of memory that Intel has called the “Rambo Cache”, one of the key pieces for Intel Xe. But what exactly is the Rambo Cache and what is its use? How do we make huge numbers of GPU integrated chips communicate efficiently with each other? We need a memory to do the intercom work and that’s where the Rambo Cache comes in handy.

Difference between Xe-HP and Xe-HPC
The Rambo Cache is a chip that includes a memory inside, which will be used exclusively in the Intel Xe-HPC for communication between the different tiles/chiplets. While the Intel Xe-HP supports up to 4 different tiles, the Intel Xe-HPC handles a much higher amount of data, which makes this additional memory chip necessary as a communication bridge for extremely complex algorithms in terms of the amount of data, GPU chiplets, or tiles as Intel calls them.

The Rambo Cache will be placed between multiple Intel Xe-HPC Compute Tiles to facilitate communication between them. Compute Tiles are nothing more than Intel Xe GPUs but specialized for high-performance computing, so the classic fixed function units in GPUs won’t be integrated in the card.
However, the Rambo Cache is not confirmed to be present in the rest of the Intel Xe architecture, especially those not based on several chips such as the Intel Xe-LP and Intel Xe-HPG. In the specific case of the Intel Xe-HP, it seems that with 4 chiplets the Rambo Cache is not necessary due to the fact that the Interposer provides enough bandwidth to communicate the different chiplets mounted on top of it.

The goal is to reach the ExaFLOP
We know that the limit regarding the number of chiplets on an interposer is 4 GPUs, but from a higher number it is when the interconnection based on an EMIB interposer no longer gives enough bandwidth for communication. This makes it imperative one component to unify the access to the memory and that is exactly the function of the Rambo Cache. It would allow Intel to produce a more complex GPU than the maximum 4 chiplets allowed through EMIB.
The objective is being able to create a hardware that combined, can reach 1 PetaFLOP (or in other words 1000 TFLOPS). A performance much higher than the GPUs that we have in PC, Although this hardware was designed for super-computers, aiming to reach the ExaFLOP milestone, which is 1000 PetaFLOPS and therefore 1 million TeraFLOPS.
The great concern of hardware architects to achieve this is energy consumption, especially in data transfer: more calculations more data moves and more data more energy. That is why it is important to keep the data as close to the processors as possible, thank to the Rambo Cache.
The Rambo Cache as a top-level memory
When we have several cores, whether we are talking about a CPU or a GPU, and we want all of them to access the same memory on both cases at a physical level, a top-level cache is needed. Its physical location within the GPU should be before the memory controller but after each kernel’s dedicated caches.
GPUs today have at least two levels of cache, the first level is deprived of shader units and is usually connected to texture units. The second level instead is shared by all the elements of a GPU. In this case, they are the interconnection path to communicate, access the most recent data and all this in order not to saturate the VRAM controller with requests.
But there is an additional level, when we have several complete GPUs interconnected with each other under the same memory, then an additional level of cache is needed to group the accesses to all the memories. Intel’s Rambo Cache is the solution to unify the access of all the GPUs conforming the Ponte Vecchio in Intel Xe architecture.
More stories like this
- Intel enters the GPU game with its Xe-HPG (DG2)
- New Intel XeSS AI Super Sampling: More FPS in games
- Comparison of the Z790 and Z690 Intel motherboard chipsets
- Who leads the battle of the CPUs in 2023?
- Intel NUC 13 Extreme Mini ITX barebone full review
- Z790 AORUS Tachyon full review